If you have been following me even casually, you would know of my obsession with understanding and applying models. Accurate modeling helps in efficient understanding of the situation, stops us from reinventing the wheel, reuse solutions that have worked before and ensures that we do not leave out anything in our analysis.
Mathematics has not been my forte but that will not prevent me from foraying into it.
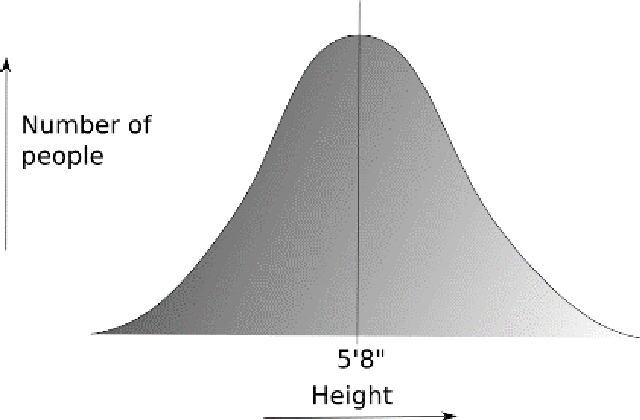 Let’s start with a Normal (Bell) distribution – a model that explains many common phenomenon. For example, distribution of marks in a typical university course and distribution of heights, weights or IQs of people in a community. It helps in finding the mean (most commonly occurring value), variance and standard deviation of other data around it. We can extract useful results and make accurate predictions.
Let’s start with a Normal (Bell) distribution – a model that explains many common phenomenon. For example, distribution of marks in a typical university course and distribution of heights, weights or IQs of people in a community. It helps in finding the mean (most commonly occurring value), variance and standard deviation of other data around it. We can extract useful results and make accurate predictions.
The normal distribution focuses on the average – and how everything relates to the average or the most common. You can identify common clusters and predominant patterns. You can see the outliers at the fringes of the bell, but they are really just at the peripheries. They are not the focus of the model. There is a reason why it is called a ‘normal’ distribution.
A more interesting model is the Power Law. It is typically used to model a relationship where the frequency of occurrence of a quantity varies as a power of some attribute of that quantity. It’s a skewed relationship where for a small set of values, the frequency of occurrence of the quantity is disproportionately different from that of others. A good example is the distribution of wealth in a society. There is a certain number of people – probably less than 2% of the population – who are disproportionately wealthier than the rest. The rest are relatively of similar wealth relative to that elite set. The distribution looks like this:

