If you have been following me even casually, you would know of my obsession with understanding and applying models. Accurate modeling helps in efficient understanding of the situation, stops us from reinventing the wheel, reuse solutions that have worked before and ensures that we do not leave out anything in our analysis.
Mathematics has not been my forte but that will not prevent me from foraying into it.
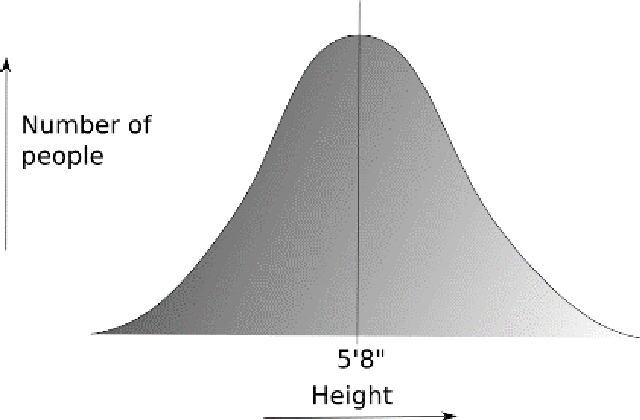 Let’s start with a Normal (Bell) distribution – a model that explains many common phenomenon. For example, distribution of marks in a typical university course and distribution of heights, weights or IQs of people in a community. It helps in finding the mean (most commonly occurring value), variance and standard deviation of other data around it. We can extract useful results and make accurate predictions.
Let’s start with a Normal (Bell) distribution – a model that explains many common phenomenon. For example, distribution of marks in a typical university course and distribution of heights, weights or IQs of people in a community. It helps in finding the mean (most commonly occurring value), variance and standard deviation of other data around it. We can extract useful results and make accurate predictions.
The normal distribution focuses on the average – and how everything relates to the average or the most common. You can identify common clusters and predominant patterns. You can see the outliers at the fringes of the bell, but they are really just at the peripheries. They are not the focus of the model. There is a reason why it is called a ‘normal’ distribution.
A more interesting model is the Power Law. It is typically used to model a relationship where the frequency of occurrence of a quantity varies as a power of some attribute of that quantity. It’s a skewed relationship where for a small set of values, the frequency of occurrence of the quantity is disproportionately different from that of others. A good example is the distribution of wealth in a society. There is a certain number of people – probably less than 2% of the population – who are disproportionately wealthier than the rest. The rest are relatively of similar wealth relative to that elite set. The distribution looks like this:

The Power law focuses on the outliers or the exceptions – those that are significantly different from the rest.
The reason this model is important is because the outliers in any phenomenon, be it social, financial or business, can play a critically important role. Simply because they are low in number does not mean they are irrelevant. In fact, in many cases they are the game-changers, the key players and the primary focus for improvements. For example, Power Law accurately models the relationship between casualties in earthquakes to the total number of earthquakes. Majority of the earthquakes are harmless. However, there is a very small number that causes the bulk of destruction. Obviously, that small set of ‘outlier’ earthquakes is of more interest.
So why is Power Law relevant to the knowledge organizations?
As you can guess, because it can model many things happening in knowledge communities and consequently help them be more effective. Here are two examples:
Sometime back I wrote about the value of mavens in our lives. They are experts on a particular topic that they are passionate about – and overly eager to help others without any expectations of return. Mavens are extremely useful folks. They are experts and they help us for nothing. However, they are also very rare. If you plot the number of people in any community that show a ‘mavenish’ tendency, you will find that only an extremely small number are mavens. Mavens in a community or population can be modeled using Power Law. They are the outliers, the exceptions, the rarity. Yet, they are extremely important.
The second example is about those who create knowledge content in a community. For example, the contributors to Wikipedia can be modeled using Power Law. Not all writers of Wikipedia create an equal amount of content. They do not even form a normal distribution where the majority is clustered around a mean. It exhibits Power Law. The biggest contributors are few and they contribute big. Such trends can be seen on any media where a community (voluntarily) is generating content. It can be your corporate wiki. It can be even your Facebook or Twitter feeds (yes and you want to kill those people!). A similar example that has always fascinated me is stackoverflow.com – a Q&A community of programmers. They ask the questions, they give the answers. Every user has a ‘reputation’ which is essentially a measure of both quantity and quality of the contribution of that person to the community (as judged by the community). Higher the reputation, bigger your contribution. The stackoverflow community is around 1.7 Million (as of June 2013). Users with reputation of over 50K are less than 500. Probably more than half would have a reputation less than 1000. You can read more details here. (You can probably see a Power Law relationship on the tags that are most discussed in stackoverflow as well).
You get the gist!
Power Law is important because it helps us realize importance of these important outliers. It helps us focus on identifying them and helping them get more effective. Any effort spent on increasing their value has a higher rate of return than a massive universal investment on the remaining majority.

John Skeet on stack overflow has quotes written around him.
What’s interesting for me though is, once you find the outliers using the power law, is there a way to push the so called “normals” towards the outside? I tried introducing stack overflow contributions in my company and I got some interesting responses:
a. Company should give us ample time to do the contributions.
b. SO rating is no measure of person’s excellence.
c. A few people went so far as to sockpuppet the SO system to prove me wrong. One of the guys got himself to more than 3000 reputation and while doing so, got other user’s accounts blocked.
If you were to encourage something like this, how would you proceed?
You should try to push the normals towards outliers – that is the continuous improvement knowledge organizations should have. However, once you have a new normal, you will have new outliers too!
Power Law (or other models) do not help in improvements, not at-least directly. They help us understand what is really happening in a natural system. The intent is to understand these models to better understand and analyze our communities, not to change them. In my opinion, no matter what you do, there will always be very few folks in your organization that will be real John Skeet approximations and others would be like the rest of SO community. In essence, your organization will be small image of the entire SO community. And that is okay. Those that are not John Skeets here, can be John Skeets for something else.
Key takeaway, in my opinion, is that you focus on these bright stars and make them better, rather than creating a homogenous mix of half-Skeets.
Pingback: In God we trust; all others bring data | Thinking Spirits …
Ather, nice post. However, a very important part of the power law distribution is (when talking about probabilities esp) is the “heavy tail” distribution. To explain that you need to bring in the exponential or poisson distribution (like normal, also easy to mode) but which assumes an asymptotically zero probability for values on further down on the x-axis. The Power law also shows that real world distributions have a significant number of people that contribute a small amount, but they are a lot of them. Thus to understand the full trend, ignoring them is wrong —- which would imply focusing on your “mavens” leads to counter productive results.
I hope this makes sense 🙂
Thanks Affan, yes it makes good sense. I agree that both heavyweights and the heavy-long tail are relevant – neither can be ignored. The idea is to understand the process happening underway and then make good use of those insights. There are certain cases where we may focus more on one or the other, depending on the situation or underlying process, but realizing that both exist and relevant for consideration is important.
Pingback: Happy Birthday Thinking Spirits! | Thinking Spirits ...